











In January, the apica.io team shipped plenty of new features, enhanced existing ones, and squashed a few bugs to make your Active observability and data pipeline control and storage experience using the apica.io platform better than ever before. This blog captures the key features and enhancements we pushed last month. If you’d like to receive product updates like this in your inbox, subscribe to our monthly newsletter here.????
We’ll also be publishing our changelog on our blog every month.
New forwarders
The LogFlow platform now includes built-in data forwarders for IBM QRadar and DataDog. Users can now replay current and historical data from any time range to their DataDog and IBM QRadar instances on-demand and in real-time. These new forwarders make it easier for DataDog and IBM QRadar users to use InstaStore as a catch-all data dam for their data, enhance data value, augment security events, and significantly reduce EPS before shipping data to these platforms.
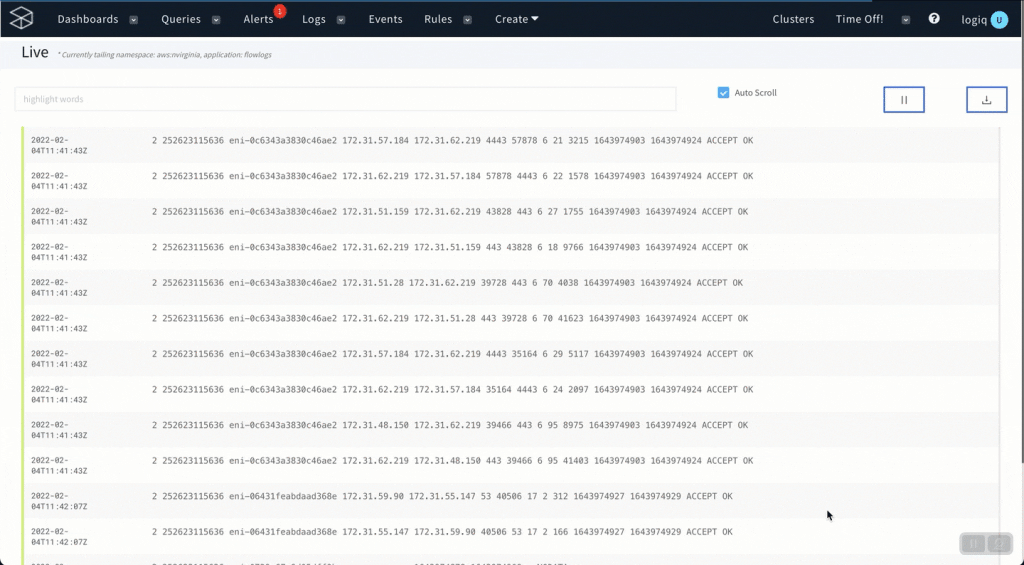
Live tail logs on the Apica UI
You can now live tail logs within the Apica UI. To tail logs, select the log stream from the Logs page, click Options and then Live Logs. Doing so opens a new page that displays your logs as they’re being ingested into Apica. You can also use the search box to perform a high-level search to highlight keywords within logs as you tail them.
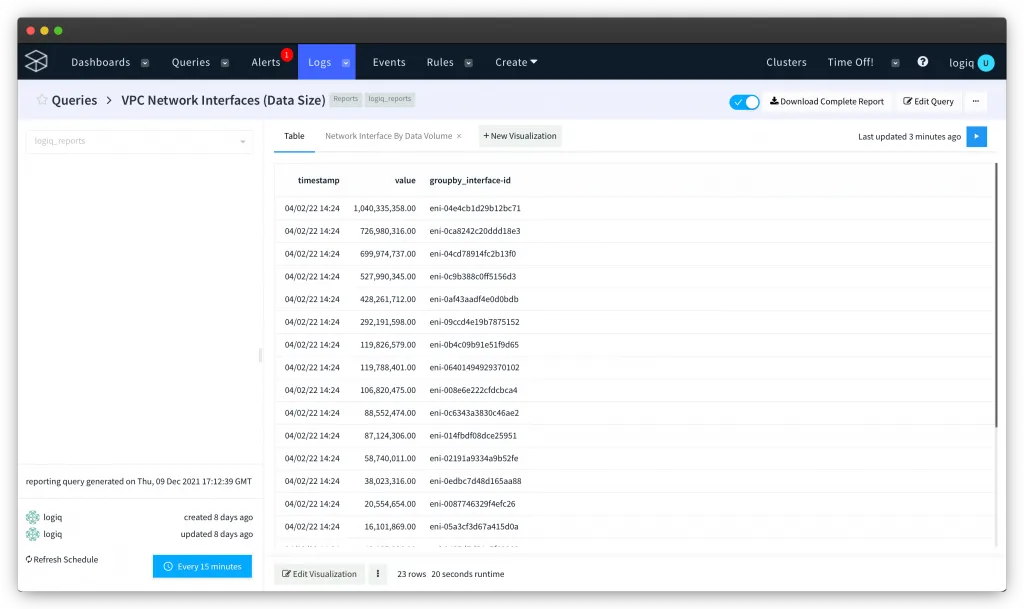
Do more with Reports
The Reports UI time series reports against a series of data points collected over custom timestamps and periods that you specify. The Reports page also allows you to download raw report data to your local machine.
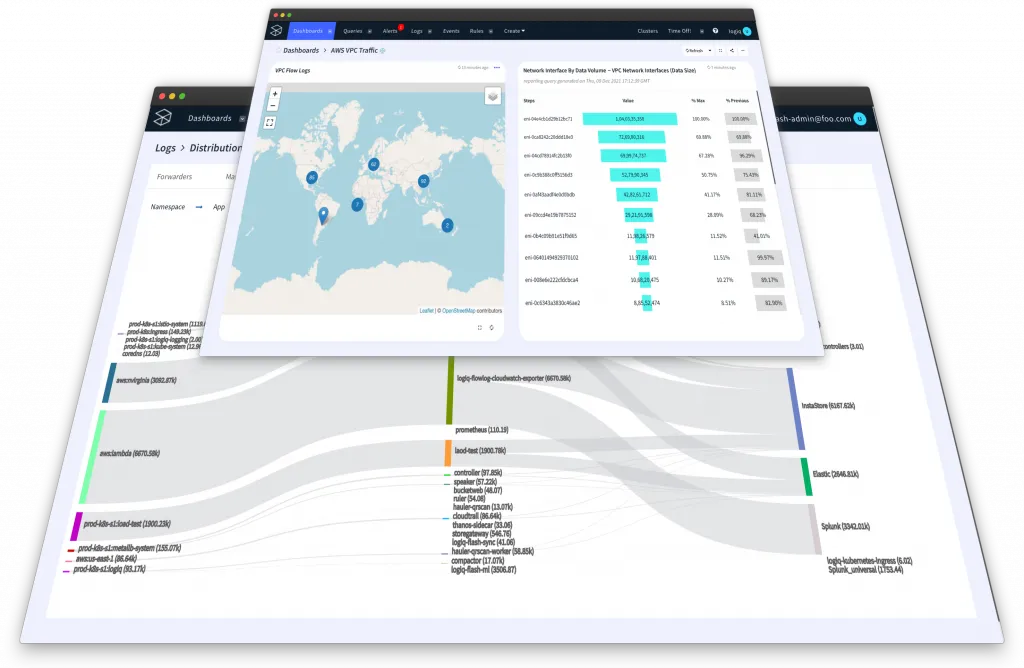
Maps, Funnels, Sunbursts, Sankeys, and Cohorts – Oh My!
We’ve added new chart types and dashboard widgets to visualize your data better. You can now visualize your data into map views, funnels, Sunbursts, Sankey graphs, and cohort tables. You can now build more comprehensive dashboards that bring your data to life and help you go from raw data to insights faster than ever before.
Rule the Roost
The built-in Rule Pack library is now more expansive than ever. We added new Rule Packs for Microsoft IIS, JBoss, Qualys, and Zoho ManageEngine. We’ve also added more pre-built rules into the PII, SQL, and Kubernetes Rule Packs, among several others.

We’ll continue to enhance our existing feature set and push new features to help you build and exercise better control over your observability data pipelines. What would you like us to develop or improve next? Drop us a line and let us know. You could also reach out if you’d like to learn more about these new features, schedule a demo, or witness first-hand how you can quickly streamline, observe, and operationalize observability and machine data using Apica.
