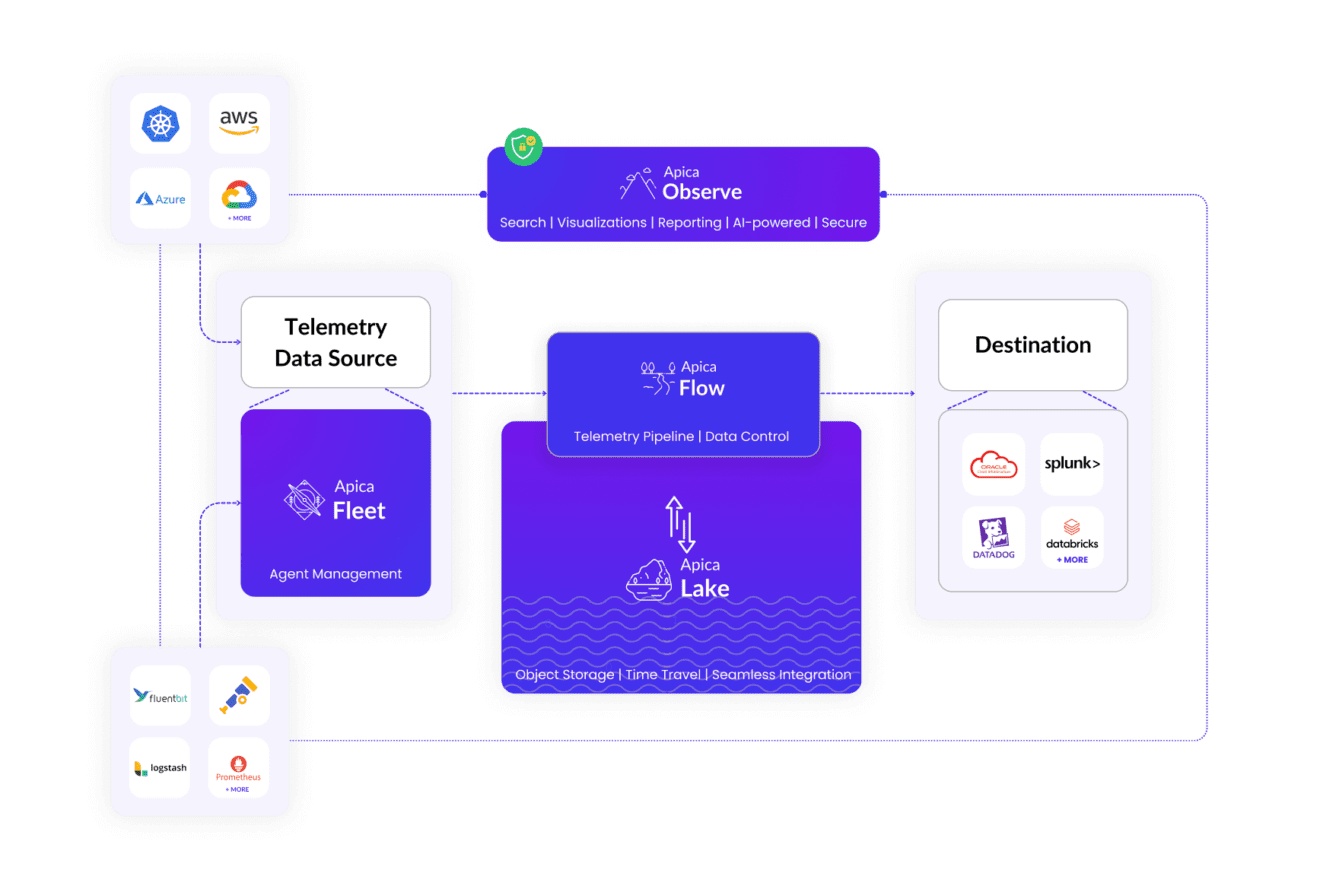
Apica’s Flow telemetry pipeline solution revamps data flow between sources and destinations, making data management and enterprise observability easier and more efficient.
From complete data control to creating customizable data lakes, Flow equips you with the following key capabilities:
- 100% data ownership: Aggregate logs from multiple sources and enhance data quality.
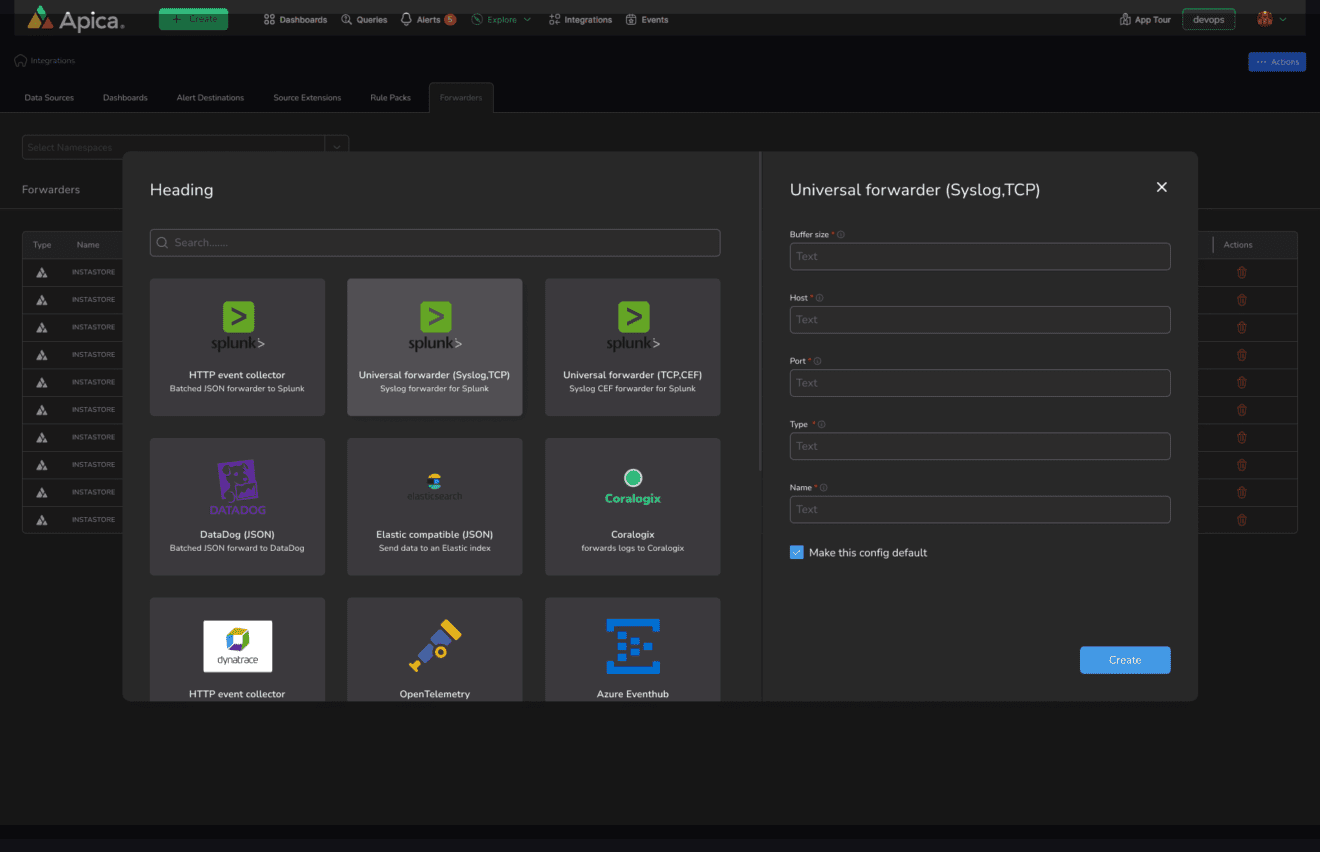
- Build robust data pipelines: Easy integration with support for open standards.
- Create data lakes: Develop customizable data lakes for optimal performance.
- Trim excess data: Reduce costs by filtering out non-essential data.
- Augment data attributes: Enhance logs with additional attributes and security events.
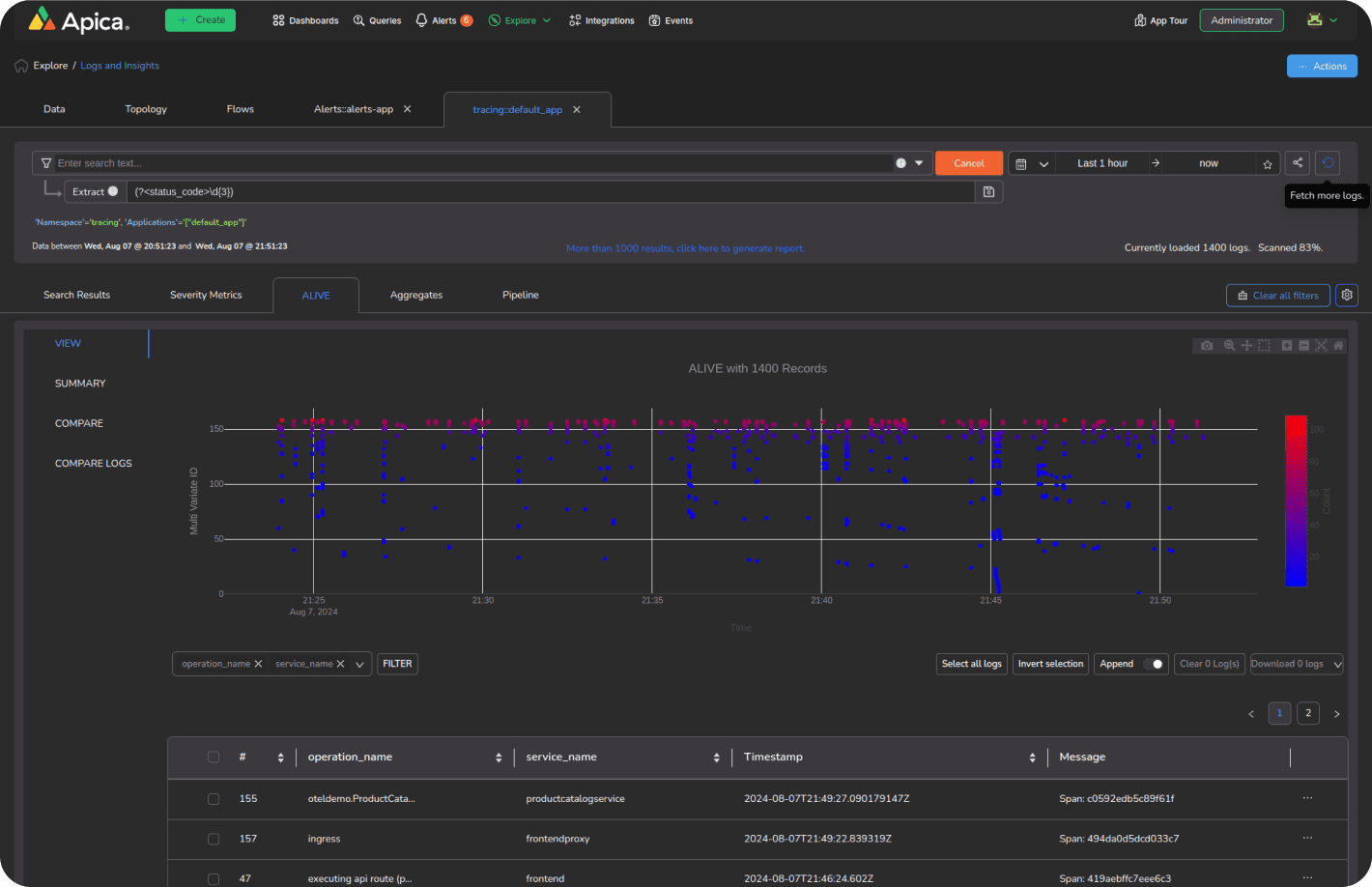
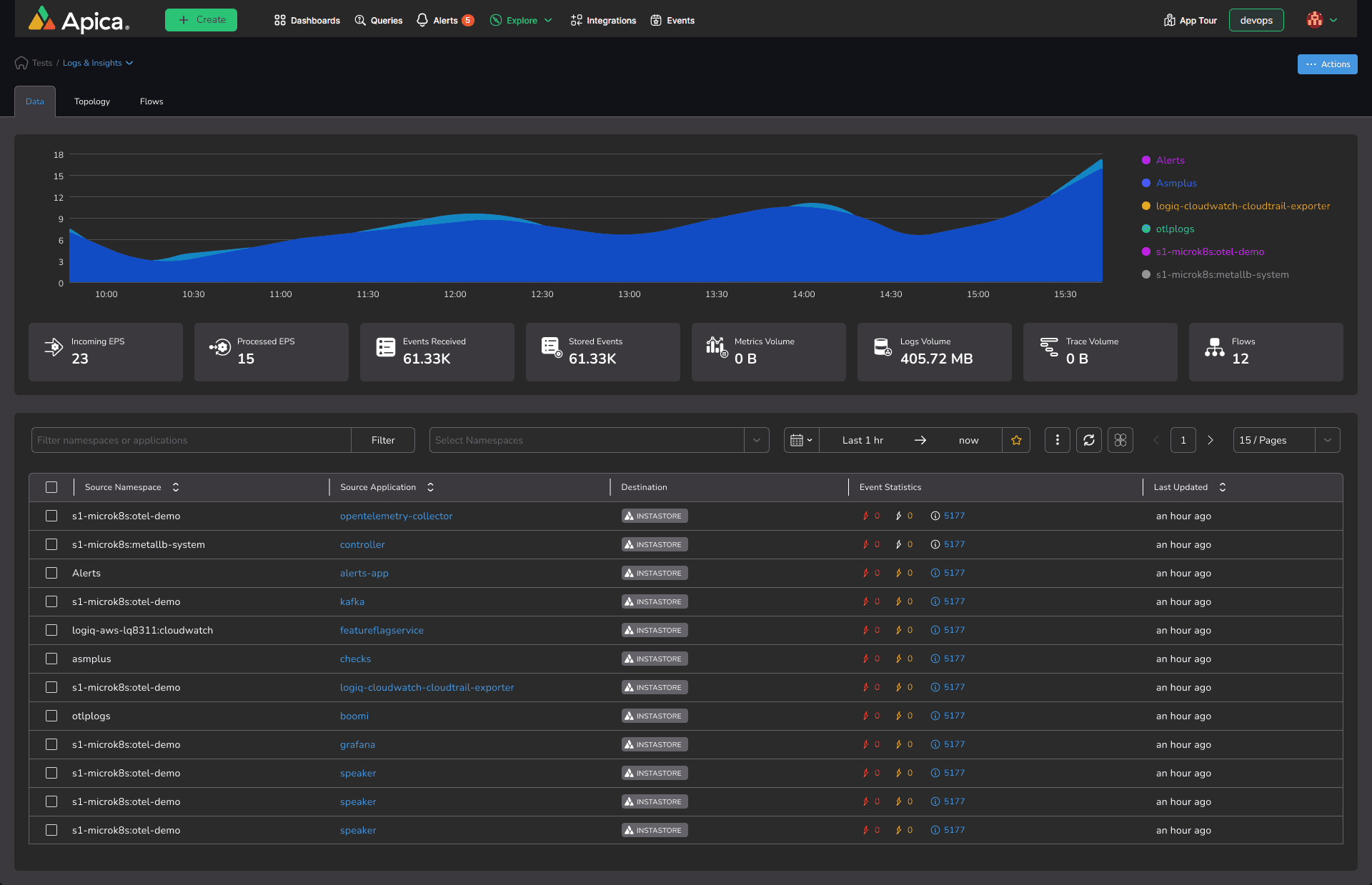
Integrating Flow into your telemetry pipeline, you can enhance observability, ensuring that the data collected across your systems is processed efficiently and actionable insights are delivered for proactive decision-making.
Auto scale-out architecture is essential in today’s data-intensive environments, as scale-up architectures are unable to cope with the rapid growth and diverse data sources. Apica’s architecture focuses on dynamically expanding compute and storage resources to accommodate increasing data loads, rather than simply upgrading existing resources.
Built on a native Kubernetes (K8s) platform, Apica automatically adapts to fluctuating data streams and rates by proportionally scaling bandwidth, compute, storage, and throughput. Utilizing Kubernetes containers for computing and object storage for data management, our architecture facilitates seamless auto-scaling to address ever-evolving data demands.
- Dynamic resource expansion
- Kubernetes and Object Storage-based architecture
- Seamless auto-scaling
Unlike many systems such as Splunk, Datadog, Grafana, and Dynatrace, which claim to have decoupled storage and compute, Apica achieves complete decoupling by separating both indexing and retention capacities from compute resources. This results in reduced complexity, enhanced flexibility, and cost optimization in handling the critical dimensions of observability data: volume and retention.
- True compute and storage decoupling
- Addresses data volume and retention challenges
- Fully decoupled ingest, indexing, and retention capacities
For enterprises evaluating data observability tools, Apica’s storage layer leverages any object store or S3-compatible storage as its primary storage layer , allowing the system to accommodate theoretically infinite data growth due to ingestion or long-term retention requirements. This approach provides unparalleled operational agility compared to other industry solutions. Data retention at any volume, from terabytes to petabytes, is consistently managed by the Apica architecture.
Apica is the first real-time platform to combine the advantages of object storage, such as scalability, one-hop lookup, fast retrieval, ease of use, identity management, lifecycle policies, and data archiving. While other self-service log analytics solutions may require expensive management for large-scale volumes, Apica simplifies this process by abstracting it as an S3 API.
- Utilizes object storage or S3-compatible storage
- Theoretically infinite storage capacity
- Consistent handling of TBs or PBs of data
Apica leverages Kubernetes containers for its compute layer, enabling the inherent benefits of autoscaling. Administrators can automatically increase or decrease the number of running pods based on changing data rates. The system efficiently handles data load spikes or gradual increases without manual intervention. Kubernetes Autoscaler ensures the platform can manage surging data rates by scaling out pods and nodes as needed.
The scale-out architecture of Apica allows for seamless ingestion at any scale, from gigabytes to petabytes per second, using a consistent architecture. By incorporating AI/ML-driven algorithms for capacity planning, Apica delivers infinite scale capabilities in a hands-off, worry-free manner.
- Autoscaling with Kubernetes containers
- Dynamic pod/node scaling for fluctuating data rates
- Seamless ingestion at GBs, TBs, and PBs per second
Apica achieves the lowest Total Cost of Ownership (TCO) by minimizing infrastructure costs and optimizing resource utilization. By using containers and Kubernetes deployments, Apica provides simple management, high availability, fault tolerance, and improved end-user productivity at a lower cost compared to virtual machines and bare-metal servers.
In addition, Apica employs object storage as primary storage, offering similar architectural benefits as Kubernetes does for compute. This results in a Zero Storage tax model for end-users, simplifying both Day 0 and ongoing operations while eliminating storage overheads. Consequently, Apica delivers the lowest possible TCO for scaling storage operations in response to growing data needs.
- Reduced infrastructure costs
- Efficient resource utilization
- Zero Storage tax model
Apica’s distributed Kubernetes-based compute architecture ensures optimal performance-to-scale ratio, enabling real-time ingestion and processing of high-volume data streams. Although S3-compatible storage systems are commonly considered secondary or cold storage, Apica’s innovative engineering delivers real-time query performance with object storage. This unique approach is ideally suited for the observability use case and potentially adaptable for other applications in the future.
- Distributed Kubernetes architecture
- Real-time data ingestion and processing
- Innovative object storage performance