
AIOps and Observability have been in the limelight for a while now. Chances are that you’ve already heard about their potential to revolutionize the IT world. However, data shows that most organizations are still not using them to their fullest potential.
With IT teams struggling to keep up with the ever-growing complexity of IT infrastructure, these technologies are seen as a promising way of empowering and unlocking real-time insights. But what exactly are Observability and AIOps? And how can they help IT and DevOps teams?
In this article, we’ll take a deep dive into the world of Observability and AIOps to explain what they are, how they work together, and the benefits that can be achieved by implementing them in your IT operations for your enterprise.
We’ll look at how Observability helps IT teams to monitor their applications and services more efficiently, as well as leveraging it to gain real-time insights into the performance of their applications and services. We’ll also explore how AIOps can automate incident detection, alerting, and response in order to improve overall IT operations. Finally, we will discuss how these two technologies fit together and why they are essential elements of a successful DevOps strategy.
With that, let’s dive straight into it!

A quick overview of the key Observability Benefits
Observability in the context of cloud computing refers to the ability to monitor, measure, and analyze the behavior of cloud-based systems and applications in order to gain insights into their performance, health, and usage.
Observability provides the following benefits:
Early problem detection
Faster issue resolution
Improved collaboration
Better system performance
Increased agility
Improved CX
A Brief Overview of AIOps
AIOps stands for Artificial Intelligence for IT Operations, and it refers to the application of machine learning and artificial intelligence techniques to enhance and automate various IT operations tasks. The goal of AIOps is to provide IT teams with real-time insights and analytics, automated workflows, and intelligent decision-making capabilities that improve the efficiency, speed, and accuracy of IT operations.
AIOps leverages advanced analytics to process and analyze vast amounts of data generated by IT operations, including logs, metrics, and events. By using machine learning and AI algorithms, AIOps can identify patterns, detect anomalies, and perform root cause analysis to help IT teams identify and address issues faster and more accurately.
Some common use cases for AIOps include:
- Automated incident management
- Performance monitoring
- Capacity planning
- Predictive maintenance
Furthermore, AIOps can also help to streamline IT operations by automating routine tasks, providing proactive alerts, and reducing the manual effort required for tasks like troubleshooting and remediation.
What is Observability in AIOps?
Observability in AIOps refers to the ability to understand the behavior of complex IT systems through the collection, analysis, and visualization of data generated by these systems. It involves monitoring and measuring the performance and health of an application or system, collecting metrics, logs, and traces, and providing insights into their behavior.
Observability is critical for AIOps because it enables IT teams to identify and troubleshoot problems in real-time, without having to wait for users to report them. By collecting data from various sources, including infrastructure, application logs, and network traffic, observability provides a complete view of the system, allowing IT teams to identify and remediate issues quickly.
AIOps uses machine learning algorithms to analyze and derive insights from the data collected through observability. These insights help IT teams to detect anomalies, predict problems, and automate incident management processes. By using observability and AIOps, IT teams can proactively manage IT operations, minimize downtime, and improve the overall performance of their systems.
How do AIOps automate incident detection and alerting?
AIOps can help automate incident detection and alerting in the following ways:
- Event Correlation: AIOps platforms can ingest and correlate large volumes of IT events and logs from various sources such as servers, applications, network devices, and cloud platforms. AIOps platforms use machine learning algorithms to identify patterns and anomalies in the data to detect incidents and alert IT teams.
- Baseline Creation: AIOps platforms can create a baseline of normal behavior for IT systems and applications by analyzing historical data. Any deviation from this baseline can be flagged as an incident, which can trigger an alert to IT teams.
- Root Cause Analysis: AIOps platforms can use machine learning algorithms to perform root cause analysis on incidents. By analyzing historical data and identifying patterns, the AIOps platform can pinpoint the underlying cause of an incident and suggest actions to resolve the issue.
- Predictive Analytics: AIOps platforms can also use predictive analytics to detect potential incidents before they occur. By analyzing patterns in data and identifying anomalies, the AIOps platform can identify potential issues and alert IT teams before they become critical.
- Automated Remediation: AIOps platforms can also be used to automate remediation for common incidents. For example, an AIOps platform can automatically restart a failed service or application, reducing the need for manual intervention.
ln a Nutshell, AIOps can help IT teams improve incident detection and alerting by automating processes that were previously manual and time-consuming.
How does Apica integrate AIOps and Observability Capabilities?
apica.io leverages AIOps and observability to help enterprises manage their complex IT environments more effectively. By using machine learning algorithms to analyze large volumes of data generated by systems and applications, Apica’s AIOps capabilities can detect anomalies and potential issues before they become major problems. This proactive approach helps IT teams address issues quickly, reducing downtime and improving overall system performance.
Here are some of Apica’s AIOps capabilities:
Anomaly detection: Machine-learning algorithms can detect anomalies in system behavior and alert IT teams to potential issues before they become major problems.
Root cause analysis: Automatically identify the root cause of an issue by analyzing data from multiple sources, reducing the mean time to resolution (MTTR) for IT incidents.
Predictive analytics: Predict future performance issues and recommend actions to prevent them by analyzing historical data.
Automated remediation: Automate incident response processes, such as restarting services or scaling resources, based on predefined rules and policies.
Intelligent alerting: With Apica’s intelligent alerting, IT teams receive only relevant alerts based on their roles and responsibilities, reducing alert fatigue and improving incident response times.
Capacity planning: Forecast resource utilization trends and help organizations optimize their infrastructure capacity to meet demand while minimizing costs.
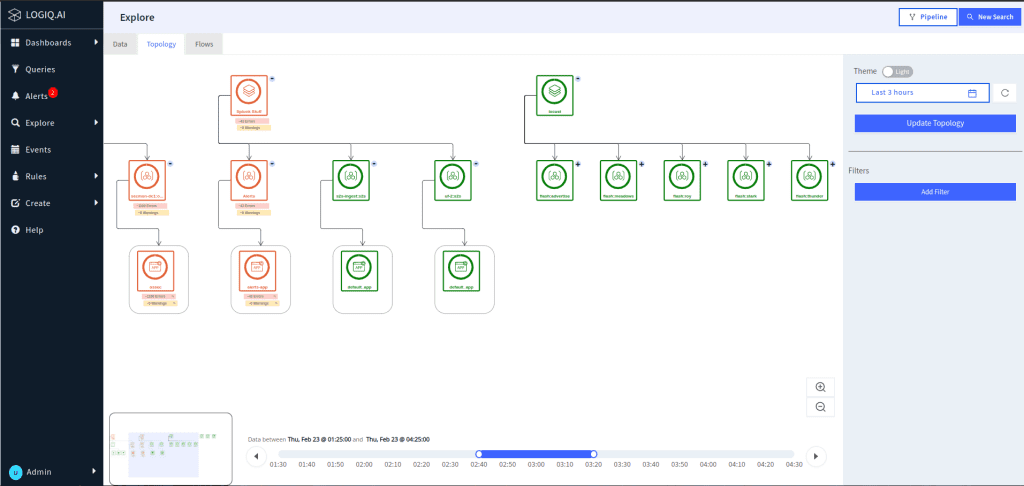
These preceding capabilities enable enterprises to proactively manage their IT environments with greater efficiency and effectiveness, reducing downtime and improving system performance.
Moreover, Apica’s observability features provide deep insights into the behavior of applications and infrastructure components across the entire technology stack. This allows IT teams to identify bottlenecks, optimize resource utilization and troubleshoot issues faster. With Apica’s AIOps and observability capabilities, enterprises can improve their operational efficiencies, reduce costs, and deliver better user experiences for their customers.
In conclusion, Apica helps enterprises manage their complex IT environments more effectively by leveraging machine learning algorithms to detect anomalies and predict future performance problems.
Register now to get automated remediation capabilities and capacity planning tools to optimize your infrastructure and improve your cloud operational efficiencies.
In a Glimpse
- apica.io leverages AIOps and observability to help enterprises manage their complex IT environments more effectively.
- Machine learning algorithms are used to detect anomalies in system behavior, identify root causes of issues and predict future performance problems before they become major issues.
- Automated remediation capabilities can be used to automate incident response processes based on predefined rules and policies, while intelligent alerting reduce alert fatigue for IT teams.
- Capacity planning helps organizations optimize their infrastructure capacity while minimizing costs, improving operational efficiencies, and delivering better user experiences for customers.



