
Log aggregation tools : Design Considerations
Log aggregation tools are essential for a company to be agile and secure. Log management is not only used for troubleshooting issues but is also the building block for any security strategy being adopted by an enterprise.
We recently looked up and close at how a top-performing cloud company had architected its log management infrastructure and the log aggregation tools that it used for their implementation in AWS. This write-up first describes the log system implementation observed on AWS at the company. We will then explore the architecture and see why solutions like this, while popular, results in an architecture that is hard to manage over time with growing costs, and resource usage.
Centralize log management is always a preferred solution for handling enterprise logging. Application, IT system, and cloud micro-service logs are collected and managed in one central location, for example, AWS elasticsearch.
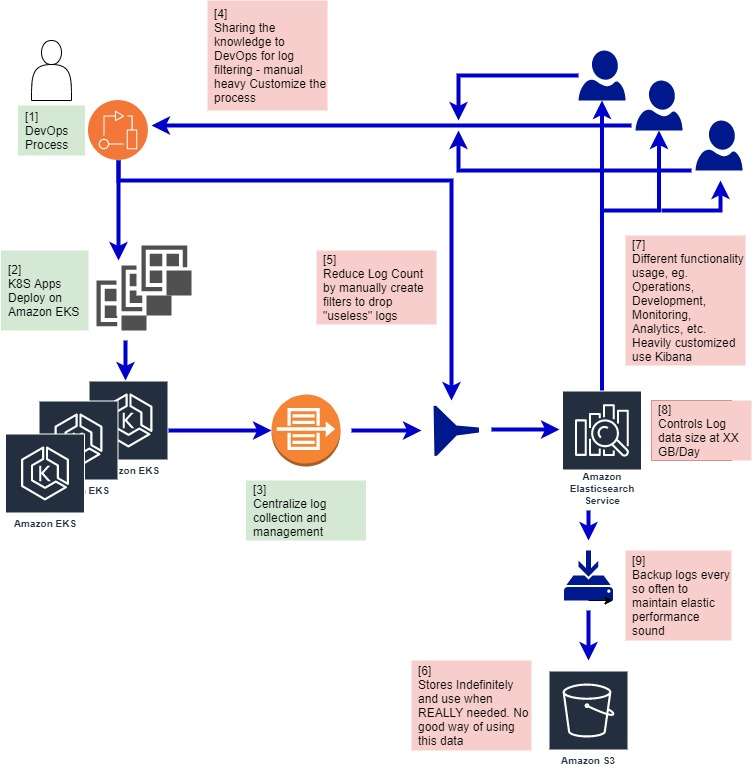
DevOps and automation teams play a central role in developing and maintaining the log management infrastructure. This mean source level log monitoring and log analysis preparation needs to be done first. See [1]. As nice as the system looks from an overview diagram, there are engineering overheads to address the infrastructure’s computing, storage, and budget resource limitation.
The ingestion pipeline first filters the log files by extracting the useful portion of the log so as to reduce noise. The trimming directives usually come from the log data end-user, such as a data scientist or system analyst. They communicate with the DevOps/automation team to create customized log extraction filters for deployment from existing log files. The goal is to control the logging volume size and content. The DevOps/Automation team builds the ad-hoc best-effort log filters, and the process is laborious and error-prone.
This log reduction filter control is in place for the log data infrastructure limitation. In this example, it uses Amazon elastic search service. Both the compute and storage resources for indexing needs to be checked for a healthy logging system. To maintain a performing stable operating state, the total number of ingesting logs is controlled at 30GB/day, see [8], and total backlogs are retained for 2 weeks. Data are backed to an economical Amazon S3 storage after that.
Different business functional units for the company deal with different log data and different usage. For example, the performance and capacity team extracts metrics from logs to model system usage trends and forecast future demand. The customer business unit would extract metrics to analyze customer insight and creates business values for example, customer churn. The DevOps would maintain the system’s operating state over SLA (Service Level Agreement) requirement. The log data metrics extraction and the subsequent analytics are highly customized, flexible, and fluid. Each functional unit is specifically created to solve specific business problems. It is highly desirable to utilize AI/ML techniques and methodology, see [7]. For example, holistically, log ingestion data pipe can be enhanced with tag or label to facilitate later AI/ML analysis. All the mutable fields in the log are automatically extracted for analysis.
Amazon elasticsearch infrastructure, in the design above, can scale-out, but often requires some degree of trial-and-error and knowledge of elasticsearch internals and clustering. There are other factors to consider. For e.g. how much data to store and how long. In this example, the incoming log data was capped at about 30GB/day with a 2-week log data retention time to keep the system within the operating budget, and desired system performance. The system always holds about 500GB of log records for processing. The overflown log is backup into Amazon S3 at $25/TB-month for an indefinite period. Someone needs to understand how to load this data back if it is ever needed. This is a non trivial job function. The AWS hosting of such a setup is around $60k/year, not including engineering and operator costs and knowledge base needed to manager hybrid storage design.
Here at apica.io we have solved the problem of hybrid storage designs for log management. Here is a similar log infrastructure setup using Apica building blocks. The system now becomes simpler because storage limitations are alleviated with the use of S3 storage as primary data store. You have now significantly simplified the log aggregation tools that you need to run this with minimal overheads. See figure below,
Apica log management infrastructure removes the engineering build-in infrastructure overhead. The new construct is efficient and straightforward. The table below lists the infrastructure resource engineering overheads, and the list tags are from an earlier drawing
|
Tag |
Description |
Overhead Action |
Apica |
|
[4] |
Need for reducing log ingestion to save log process resources. Consult and communicate with log end-user. |
The process is error-prone due to log and apps changes and requirements. |
Simple log data ingestion pipeline |
|
[5] |
DevOps implement log filter to reduce ingest log count |
Implementations and validate the stored log with end-user |
No need to trim log data. Store un-redacted logs into S3 storage. |
|
[8] |
Maintain constant overhead and scale-out ELK if needed |
Elastic search service does not scale seamlessly. |
Apica scales easily using K8S pods |
|
[9] |
Daily backup the oldest logs to S3 to maintain stable log working set size |
Add backup and no easy process for re-using the backup log data |
Directly operate on S3 storage– Searching, Reporting, events, AI/ML analysis, etc. |
In summary, this article describes an operating log infrastructure setup on AWS. It also presents a similar Apica log infrastructure setup. Apica log management infrastructure removes induced engineering overhead because of its competitive advantage in the native use of S3 storage.
There are plenty of references on the web about scaling elastic search service and the common consensus from these references is such a task is not for the faint heart.



