Observability and event log data are important. What’s more important, however, is the ability to figure out the relevance of the data. In other words, the means to segregate useful data from redundant ones.
With a multitude of vendors in the market promising to solve all your log and pipeline issues, it gets challenging to choose the ideal one that suits your needs. Key players like Splunk, DataDog, etc. provide observability and SIEM solutions but they don’t prove to be very cost-effective in the long run.
It’s obvious that greater data values will imply heavier cost investment. With the majority of observability platforms, you have limited pipeline control. Therefore, With the massive amount of data volume to handle and store, you end up spending exorbitantly. Most of the expenses come from the licensing and infrastructure cost that is needed to support processing and storage.
Enter Apica’s FLOW, an excellent tool designed to centralize the flow and control of the observability data pipelines. It gives you complete pipeline control without any compliance issues. In simple words, it gives you the ability to keep track of the data quality, relevance, and volume that goes through the data pipelines.
Apica’s FLOW capabilities include:
- Pipeline control simplification and optimization through the use of artificial intelligence and machine learning.
- Automatic optimization of the flow of tasks in a pipeline based on real-time data and performance metrics.
- Multiple data sources and formats support, schedule, and automate pipelines and integration with a range of tools and platforms.
- Filter/Reduce: Optimizing spending and remediation faster, 100% data control to maximize data value, Collect, optimize, store, transform, route, and replay your observability data.
- Mask/Transform: Improving compliance and interpreting better, Mask and obfuscate PII, build user-defined extraction, removal, or obfuscation rules, and visualize data pipeline in real-time.
- Enrich: Supercharging analytics and improving predictions, Rule packs for data optimization, Trimming off excess data, and Augmenting log attributes.
- Route: Send the right data to the right target every time, Concentrate on optimizing your observability and security efforts, Send high-value data to costly analytics tools while simultaneously storing a full-fidelity replica of the data in less expensive object storage, and Apica is an observability pipeline that you can easily plug into the center of an existing system.
These capabilities help to simplify and optimize pipeline control, ensure maximum efficiency and minimize the risk of bottlenecks or errors, improve compliance and data interpretation, supercharge analytics and improve predictions, and enable sending the right data to the right target every time. Additionally, it optimizes spending and remediation faster, improves data quality integration, and lowers licensing and infrastructure costs.
One of the key advantages of FLOW is its ability to automatically optimize the flow of tasks in a pipeline based on real-time data and performance metrics. By continuously monitoring the pipeline and adjusting the flow of tasks as needed, FLOW can help ensure that the pipeline is running at maximum efficiency and minimize the risk of bottlenecks or errors.
The key benefits of FLOW include:
- Collect all your logs and metrics from multiple sources and ship them to any observability platform of your choice such as Splunk, Apica, Elasticsearch, etc.
- Build robust data pipelines for improving data quality.
- Take control of your data by aggregating logs from multiple sources and forwarding them to one or more destinations of your choice.
- Trim off excess data to reduce system costs and improve performance using powerful filters.
- Convert log data to time series visualizations for anomaly detection in your data pipeline.
- Create data lakes with highly relevant data that is partitioned for optimal query performance.
- Mask and obfuscate PII in real-time using user-defined extract, remove, or obfuscate PII data in your logs.
Architecture
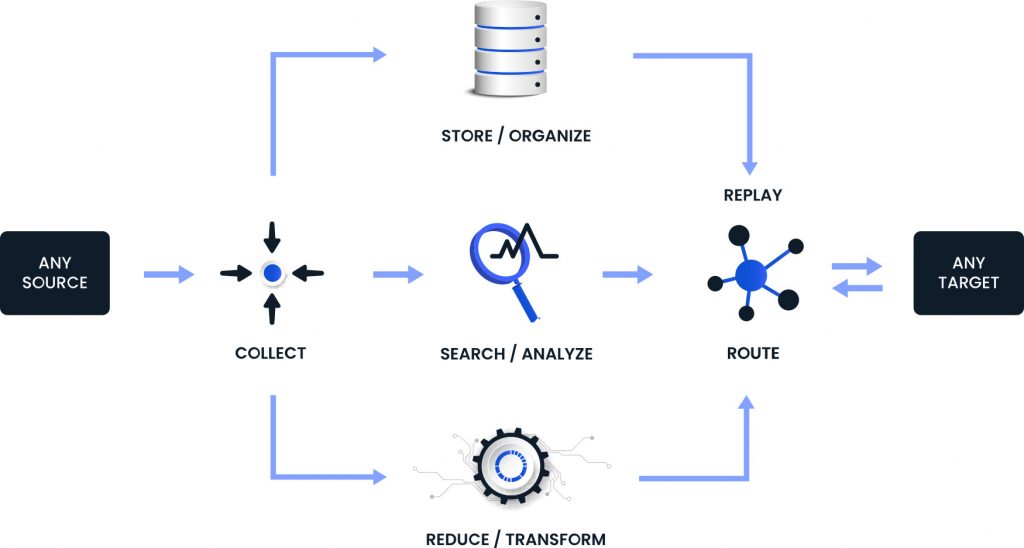
FLOW is based on elastic architecture. It is not only beneficial but also necessary to have an elastic architecture so that the data pipeline can handle data sources sending additional data automatically. If this is not done, data backlogs will clutter the source and, if they persist for a long time, data loss is bound to incur.
Moreover, Apica’s hot store platform InstaStore is meticulously designed to manage the difficulties businesses encounter in high-volume settings. Before being transmitted, all data entering FLOW is written in its entirety to InstaStore. By constructing on top of any object-store and abstracting storage as an API, InstaStore offers an endless storage layer.
From the very beginning, you can construct your data pipelines with limitless storage that can serve as an unending store for throughput discrepancies. InstaStore allows for the quick replay of any data to a target upon request. With InstaStore, you can bid farewell to the data block and data loss issues forever.
Furthermore, apica’s FLOW is built on Kubernetes and is deployable as a HELM chart in any Kubernetes environment. FLOW offers multiple deployment patterns and may be set up and customized for your business. With the help of Horizontal Pod Autoscaling and Cluster Autoscaling, it offers instant throughput when needed in high-volume data situations.
The platform can elastically scale as needed thanks to native Kubernetes design
Splunk Forwarding
The plugins provided by Apica allow for the creation of one or more Splunk Output settings, which can subsequently be used to transfer data to Splunk. Apica enables delivering data to a Standalone Server, a list of indexers, or indexers using peer discovery which is all different ways business forwarding types.
Check out the step-by-step process on how to start the Splunk plugin for output configurations in the documentation here.
Why FLOW?
| WHAT | HOW | BENEFITS |
| Enhanced quality of upstream data ingested. | Apica enables complete control of upstream data flow. | Reduce licensing and infrastructure costs of your observability investments. |
| Resolve challenges arising due to tiering. |
|
|
| 100% compliance | Object Storage is primary storage. | Compliance at the lowest TCO
Compliance cost= object storage cost. |
| Enhanced productivity | Resources used on projects that matter. | All data is searchable in real-time. |
| Less Data Growth Issues | Apica makes storage an API | No storage expansion issues |
FLOW offers a myriad of advantages by adding a pipeline control layer to your current observability solution, such as Splunk, Datadog, NewRelic, Elastic, etc. Moreover, a strong data pipeline can analyze data streams to aggregate data and increase data relevance.
The following are a few valuable reasons to augment FLOW in your pipeline control endeavors:
- Less time for response to any user data analysis request, be it internal or external. All without the costly initiatives that are typical in most organizations, data can be transferred to any location instantly.
- FLOW keeps all of its data in InstaStore. Additionally, FLOW offers instant replay to your target system whenever data that is not currently in it is required.
- The majority of enterprise data falls into the critical and non-critical categories. Customers can save money on infrastructure and license costs, lower index sizes for faster queries, and provide knowledge workers with higher-quality data by removing unnecessary or non-critical data from target systems.
- With ZeroStorageTax, get immediate storage requirement elasticity. There is no need to increase storage, limit senders, or rush to meet increased throughput demands.
Bottomline
The voluminous growth in the complexity of data and the data sprawl in recent years gave rise to new observability challenges in the enterprise. The legacy technology, siloed data, limited pipeline control, etc are a few of the many reasons that limit the tech and DevOps teams. On top of that, using dated monitoring methods brings hindrance in performance and business alike for enterprises.
The purpose of FLOW is to control and streamline the data. It helps you aggregate logs from various sources, enhancing the quality of data, and projects to one or multiple destinations.
Moreover, FLOW allows you to reduce customer response time in that it enhances the data analysis process.
It is common knowledge that to provide your company knowledge workers with increased levels of data value, IT and DevOps engineers require better technical capabilities. Therefore, more enterprise control over data volumes, diverse sources, and the sophistication of data is essential for enhancing your company’s competitiveness.
In a Glimpse:
- FLOW is a tool for centralizing the flow and control of observational data pipelines. It provides pipeline control simplification and optimization through artificial intelligence/machine learning, automatic optimization based on real-time data/performance metrics, support for multiple sources of pipeline scheduling/automation, and integration with a range of tools and platforms.
- The key benefits include: collecting logs from multiple sources; building robust data pipelines; taking control over aggregated log forwarding; trimming off excess data reducing system costs & improving performance using powerful filters; converting logs into time series visualizations for anomaly detection in the pipeline etc.; masking PII in real-time using user-defined extractions rules packs etc.; sending the right type of high-value data to costly analytics tools while storing full fidelity replica in less expensive object storage.
- FLOW capabilities include: Pipeline Control Simplification/Optimization, Automatic Optimization of Flow Tasks in a Pipeline, Multiple Data Sources/Formats Support & Integration with Tools & Platforms, Filter/Reduce for Optimal Spend and Remediation Faster; Mask/Transform for Improved Compliance & Interpretation; Enrichment to Supercharge Analytics and Improve Predictions; Route the Right Data to Right Target Every Time.



